Sql Server 分区表
当前位置:点晴教程→知识管理交流
→『 技术文档交流 』
1. 分区表简介 分区表在逻辑上是一个表,而物理上是多个表。从用户角度来看,分区表和普通表是一样的。使用分区表的主要目的是为改善大型表以及具有多个访问模式的表的可伸缩性和可管理性。 分区表是把数据按设定的标准划分成区域存储在不同的文件组中,使用分区可以快速而有效管理和访问数据子集。 1.1> 适合做分区表的情况 ◊ 数据库中某个表的数据很多,在查询数据时会明显感觉到速度很慢,这个时候需要考虑分区表; ◊ 数据是分段的,如以年份为分隔的数据,对于当年的数据经常进行增删改查操作,而对于往年的数据几乎不做操作或只做查询操作,这种情况可以使用分区表。对数据的操作如果只涉及一部分数据而不是全部数据的情况可以考虑分区表,如果一张表的数据经常使用且不管年份之类的因素经常对其增删改查操作则最好不要分区。 1.2> 分区表的优点 ◊ 分区表可以从物理上将一个大表分成几个小表,但是从逻辑上来看还是一个大表。 ◊ 对于具有多个CPU的系统,分区可以对表的操作通过并行的方式进行,可以提升访问性能。 2. 创建分区表步骤 创建分区表的步骤分为5步: (1)创建数据库文件组 (2)创建数据库文件 (3)创建分区函数 (4)创建分区方案 (5)创建分区表 2.1> 创建数据库文件组 新建示例数据库Northwind,创建数据库文件组和文件,添加文件组。 2.2> 创建数据库文件 创建数据文件,并为数据文件分配文件组。 完成创建后的数据库文件信息 通过SQL Server Profiler可以看到具体的创建数据库的脚本如下: CREATE DATABASE [Northwind]
CONTAINMENT = NONE ON PRIMARY ( NAME = N'Northwind', FILENAME = N'F:\Database\Northwind\Northwind.mdf' , SIZE = 5120KB , FILEGROWTH = 1024KB ),
FILEGROUP [SECTION2010] ( NAME = N'Northwind_Data_2010', FILENAME = N'F:\Database\Northwind\Northwind_Data_2010.ndf' , SIZE = 5120KB , FILEGROWTH = 1024KB ),
FILEGROUP [SECTION2011] ( NAME = N'Northwind_Data_2011', FILENAME = N'F:\Database\Northwind\Northwind_Data_2011.ndf' , SIZE = 5120KB , FILEGROWTH = 1024KB ),
FILEGROUP [SECTION2012] ( NAME = N'Northwind_Data_2012', FILENAME = N'F:\Database\Northwind\Northwind_Data_2012.ndf' , SIZE = 5120KB , FILEGROWTH = 1024KB ),
FILEGROUP [SECTION2013] ( NAME = N'Northwind_Data_2013', FILENAME = N'F:\Database\Northwind\Northwind_Data_2013.ndf' , SIZE = 5120KB , FILEGROWTH = 1024KB ),
FILEGROUP [SECTION2014] ( NAME = N'Northwind_Data_2014', FILENAME = N'F:\Database\Northwind\Northwind_Data_2014.ndf' , SIZE = 5120KB , FILEGROWTH = 1024KB ) 查看数据库文件组SQL语句:
2.3> 创建分区函数 创建分区函数Transact-SQL语法: CREATE PARTITION FUNCTION partition_function_name ( input_parameter_type )AS RANGE [ LEFT | RIGHT ]
FOR VALUES ( [ boundary_value [ ,...n ] ] )
[ ; ]参数: partition_function_name:分区函数的名称。 分区函数名称在数据库内必须唯一,并且符合标识符的规则。 input_parameter_type:用于分区的列的数据类型。 当用作分区列时,除 text、ntext、image、xml、timestamp、varchar(max)、nvarchar(max)、varbinary(max)、别名数据类型或 CLR 用户定义数据类型外,所有数据类型均有效。 boundary_value:为使用 partition_function_name 的已分区表或索引的每个分区指定边界值。 如果 boundary_value 为空,则分区函数使 partition_function_name 将整个表或索引映射到单个分区。 只能使用 CREATE TABLE 或 CREATE INDEX 语句中指定的一个分区列。 LEFT | RIGHT 指定当间隔值由 数据库引擎 按升序从左到右排序时,boundary_value [ ,...n ] 属于每个边界值间隔的哪一侧(左侧还是右侧)。 如果未指定,则默认值为 LEFT。 示例:创建将用于Order表的分区函数 CREATE PARTITION FUNCTION Function_DateTime ( DATETIME )完成创建分区函数之后,可以通过以下SQL语句查看已创建的分区函数情况。 SELECT * FROM sys.partition_functions2.4> 创建分区方案 分区方案的作用是将分区函数生成的分区映射到文件组中去,分区方案是让SQL Server将已分区的数据放在哪个文件组中。 在当前数据库中创建一个将已分区表或已分区索引的分区映射到文件组的方案。 已分区表或已分区索引的分区的个数和域在分区函数中确定。 必须首先在 CREATE PARTITION FUNCTION 语句中创建分区函数,然后才能创建分区方案。 创建分区方案的Transact-SQL语法: CREATE PARTITION SCHEME partition_scheme_nameAS PARTITION partition_function_name[ ALL ] TO ( { file_group_name | [ PRIMARY ] } [ ,...n ] )[ ; ]参数: partition_scheme_name:分区方案的名称。 分区方案名称在数据库中必须是唯一的,并且符合标识符规则。 partition_function_name:使用分区方案的分区函数的名称。 分区函数所创建的分区将映射到在分区方案中指定的文件组。 partition_function_name 必须已经存在于数据库中。 单个分区不能同时包含 FILESTREAM 和非 FILESTREAM 文件组。 ALL:指定所有分区都映射到在 file_group_name 中提供的文件组,或映射到主文件组(如果指定了 [PRIMARY]。 如果指定了 ALL,则只能指定一个 file_group_name。 file_group_name | [ PRIMARY ] [ ,...n]:指定用来持有由 partition_function_name 指定的分区的文件组的名称。 file_group_name 必须已经存在于数据库中。
示例:创建将用于Order表的分区方案 CREATE PARTITION SCHEME Scheme_DateTime分区函数和分区方案创建之后,可以在数据库的【存储】中查看:
通过可以通过以下SQL语句查看已创建的分区方案: SELECT * FROM sys.partition_schemes2.5> 创建分区表 CREATE TABLE [Order](
OrderID INT IDENTITY(1,1) NOT NULL,
UserID INT NOT NULL,
TotalAmount DECIMAL(18,2) NULL,
OrderDate DATETIME NOT NULL) ON Scheme_DateTime ( OrderDate )这里需要注意分区表不能再创建聚集索引,因为聚集索引可以将记录在物理上顺序存储,而分区表是将数据存储在不同的表中,这两个概念是冲突的,所以在创建分区表时不能再创建聚集索引。 完成Order表创建之后,查看表的属性,可以看到Order表已经是分区表。
3. 操作分区表 3.1> Insert数据 USE [Northwind] GO INSERT INTO [dbo].[Order] ([UserID],[TotalAmount] ,[OrderDate]) VALUES (1 ,10.00 ,'2009-10-20'); INSERT INTO [dbo].[Order] ([UserID],[TotalAmount] ,[OrderDate]) VALUES (1 ,20.50 ,'2009-12-31'); INSERT INTO [dbo].[Order] ([UserID],[TotalAmount] ,[OrderDate]) VALUES (2 ,40.00 ,'2010-01-20'); INSERT INTO [dbo].[Order] ([UserID],[TotalAmount] ,[OrderDate]) VALUES (3 ,40.00 ,'2010-10-20'); INSERT INTO [dbo].[Order] ([UserID],[TotalAmount] ,[OrderDate]) VALUES (4 ,50.00 ,'2011-10-20'); INSERT INTO [dbo].[Order] ([UserID],[TotalAmount] ,[OrderDate]) VALUES (5 ,60.00 ,'2012-10-20'); INSERT INTO [dbo].[Order] ([UserID],[TotalAmount] ,[OrderDate]) VALUES (5 ,60.00 ,'2012-10-20'); INSERT INTO [dbo].[Order] ([UserID],[TotalAmount] ,[OrderDate]) VALUES (6 ,70.00 ,'2013-10-20'); INSERT INTO [dbo].[Order] ([UserID],[TotalAmount] ,[OrderDate]) VALUES (10 ,90.00 ,'2014-10-20'); INSERT INTO [dbo].[Order] ([UserID],[TotalAmount] ,[OrderDate]) VALUES (9 ,100.00 ,'2015-10-20'); GO 3.2> 查询数据所在物理分区表 在分区表中使用一般的SELECT语句无法知道数据是分别存放在哪几个不同的物理表中,若要知道数据分别存放的物理表,可以使用$PARTITION函数,该函数可以调用分区函数并返回数据所在物理分区的编号。 $PARTITION的语法:$PARTITION.分区函数名(表达式) SELECT $PARTITION.Function_DateTime('2010-01-01')
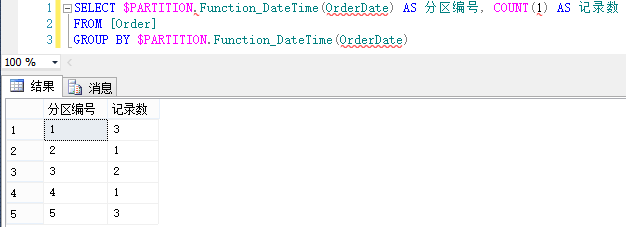
查询结果分区函数返回为1,说明2010-01-01的数据会存放在第1个物理分区表中。 使用$PARTITION函数可以具体知道每个物理分区表中存放了哪些记录。 查看物理分区表中存放的记录: SELECT * FROM [Order] WHERE $PARTITION.Function_DateTime(OrderDate) = 1
SELECT $PARTITION.Function_DateTime(OrderDate) AS 分区编号, COUNT(1) AS 记录数
FROM [Order]GROUP BY $PARTITION.Function_DateTime(OrderDate)
3.3> 修改分区表数据 UPDATE dbo.[Order] SET OrderDate='2015-01-01' WHERE OrderID = 3
4. 将普通表转换为分区表 一般的普通表都是在主键上建聚集索引,记录的物理保存位置由主键决定。 示例:创建一个Product普通表 CREATE TABLE Product
(
ProductID INT IDENTITY(1,1) NOT NULL,
ProductName VARCHAR(100) NOT NULL,
UnitPrice DECIMAL(18,2) NULL,
CreateDate DATETIME NOT NULL, CONSTRAINT PK_Product PRIMARY KEY CLUSTERED (ProductID)
)USE [Northwind]查看表Product的属性:
查看表Product的索引,可以看到PK_Product为聚集索引。
将普通表转换为分区表的操作是先在普通表上删除聚集索引,在创建一个新的聚集索引,在该聚集索引中使用分区方案。 在SQL Server中,主键字段上默认创建聚集索引,删除主键的聚集索引。 ALTER TABLE Product DROP CONSTRAINT PK_Product重新创建主键非聚集索引 ALTER TABLE Product ADD CONSTRAINT PK_Product PRIMARY KEY NONCLUSTERED (ProductID ASC)重新创建后的主键:
创建使用分区方案的聚集索引: CREATE CLUSTERED INDEX IX_CreateDate ON Product ( CreateDate )ON Scheme_DateTime ( CreateDate )调整后的Product表属性:
调整后Product表记录的物理保存情况:
5. 删除(合并)一个分区表 删除2012-01-01的分区,修改分区函数: ALTER PARTITION FUNCTION Function_DateTime() MERGE RANGE ('2012-01-01')在修改了分区函数之后,与之关联的分区方案也将同时自动调整。在执行了上面合并分区的函数之后,查看分区方案的Create脚本。 CREATE PARTITION SCHEME [Scheme_DateTime] AS PARTITION [Function_DateTime] TO ([SECTION2010], [SECTION2011], [SECTION2013], [SECTION2014])合并分区之后,被合并的分区记录也将被重新分配物理保存位置。
6. 添加分区 分区方案中指定的文件组个数比分区函数中指定的边界数大1,为分区方案指定一个可用的文件组时,该分区方案并没有立刻使用这个文件组,只是将文件组先备用着,等修改了分区函数之后分区方案才会使用这个文件组。如果分区函数没有更改,分区方案中的文件组个数也不会更改。 添加分区所需要使用到的文件组可以使用之前合并分区之后没有再使用的SECTION2012,也可以新建文件组。 ALTER DATABASE [Northwind] ADD FILEGROUP [SECTION2015]ALTER DATABASE [Northwind] ADD FILE (
NAME = N'Northwind_Data_2015',
FILENAME = N'F:\Database\Northwind\Northwind_Data_2015.ndf' ,
SIZE = 5120KB ,
FILEGROWTH = 1024KB
) TO FILEGROUP [SECTION2015]为分区方案指定一个可用的文件组: ALTER PARTITION SCHEME Scheme_DateTime NEXT USED [SECTION2015]修改分区函数,添加分区: ALTER PARTITION FUNCTION Function_DateTime() SPLIT RANGE('2015-01-01')查看添加分区后的数据物理存储:
该文章在 2024/7/22 11:27:07 编辑过 |
关键字查询
相关文章
正在查询... 



|


 400 186 1886
400 186 1886